Can the right methodology consistently produce production-quality code from an AI coding agent? Well-decomposed architecture. Maintainable code that can be refactored without disproportionate rewrites. Clean abstractions that survive the next feature.
It started with one planning skill. I was tired of Claude Code implementing features freestyle, producing code that worked but couldn’t be extended. So I wrote a /grooming skill that reads the codebase and produces a structured plan before any code is written. That helped. Then I added agent delegation to avoid context rot on long sessions. Then story points for tracking throughput. Then retrospectives and lessons to stop repeating the same mistakes across sprints. Four skills, a ~/Claude/ knowledge base, and a self-learning loop that makes the agent genuinely improve across sessions.
A note on terminology: a sprint here is one plan, one feature or refactoring task. Not a two-week time box. You might finish three sprints in a day. The rhythm is organic: finish sprint, run retro, extract lessons, start next sprint.
Why Discipline Beats Prompts
Claude Code already has built-in plan mode and cloud-based Ultra Plan with sub-agents. The tool can plan. People collect knowledge in CLAUDE.md files and skills to carry context across sessions. The building blocks exist.
What’s missing is discipline, both as tooling and as a human commitment to follow the process.
Ox Security’s research calls this the “Army of Juniors” effect: AI agents produce syntactically valid code that systematically violates engineering best practices. Fake test coverage, monolithic coupling, over-specified single-use functions.1
These aren’t prompting failures. They’re process failures. AI agents produce better code when a human reviews the plan before implementation starts, reads the diff after implementation ends, and gives structured feedback on what’s wrong and why. No skill can force you to do a thorough code review. No prompt can substitute for reading the plan and saying “each provider is imported directly in the factory method, invert this, make providers register themselves.” That’s process, and it has to come from you.
The problem with most AI-assisted workflows isn’t capability. It’s that artifacts are buried. Claude Code’s internal plans live in ~/.claude/ and aren’t meant to be browsed. Session context evaporates. You do a great code review, catch five architectural issues, the agent fixes them, and next week a different session makes the same mistakes because nothing carried the knowledge forward. Recent research formalizes this as a triple debt model: beyond traditional technical debt, AI-assisted codebases accumulate cognitive debt (the team stops understanding the code) and intent debt (thousands of unstated assumptions baked into generated code).
The framework I ended up with externalizes artifacts into a structured, persistent directory. ~/Claude/ becomes the project’s knowledge base: every plan, every retrospective, every lesson is a markdown file I can read in Obsidian, annotate, and track over time. The agent’s work becomes reviewable, measurable, and improvable.
Addy Osmani put it well in “Beyond Vibe Coding”: the developers who get the best results from AI tools are the ones who impose structure. Cursor’s engineering blog says the same: “The most impactful change you can make is planning before coding.” But planning alone isn’t enough. You need review, feedback, and a mechanism that carries knowledge forward.
You can tell an LLM “don’t duplicate code” a thousand times. Or you can build a system where it reads its own past mistakes before starting work. I went with the system.
The Ceremonies
The sprint cycle:
/groomingproduces a plan- Human reviews and approves the plan
/implementexecutes the plan- Human does code review, gives feedback
/retroanalyzes the sprint/lessonsextracts reusable rules
Steps 1-2 are one Claude Code session. Steps 3-6 are another.
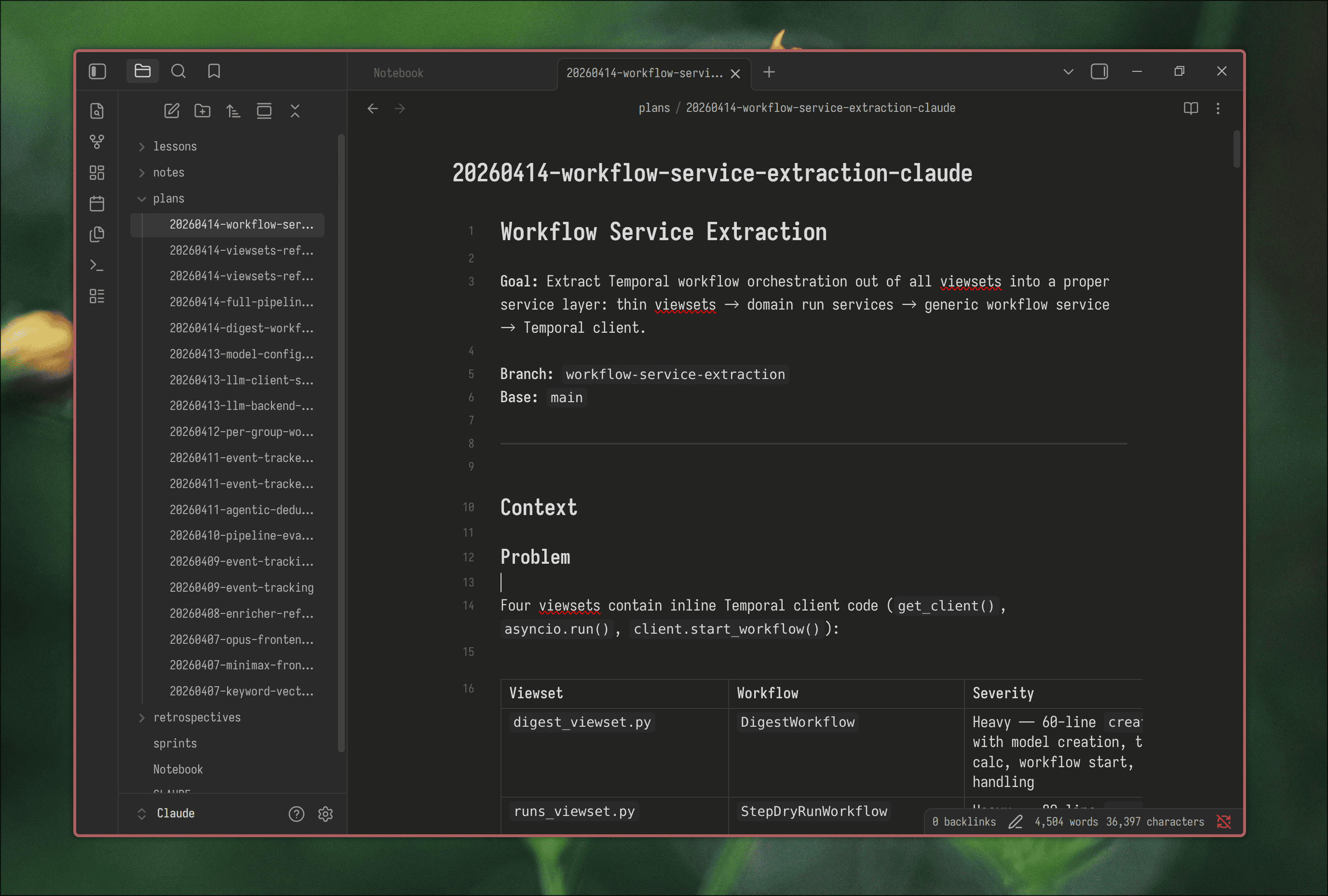
Let me walk through the system using a single sprint as an example. The project is a Django/Temporal news aggregation pipeline, a personal project I use both as a product and as a playground. Half the codebase was built by fast boopin’ with Claude Code in earlier iterations, so there’s plenty of tech debt to work through. The old LLM client module was heavily used across multiple pipeline steps, but its design conflated provider identity with model identity through fragile string parsing, and adding a new provider meant touching multiple files. The goal: replace it with a clean module where providers are explicit, model references are typed, and the whole thing is testable.
/grooming: Planning
The planning skill reads the project codebase, researches approaches, and produces a structured plan document. A full implementation plan with milestones, tasks, explicit Definition of Done for each task, architectural decisions, and a file manifest.
Plans are saved to ~/Claude/ with a date prefix (20260413-llm-client-service.md). I open them in Obsidian alongside the code. The plan becomes the contract between me and the agent for the sprint.
Each task gets story points on a 1-5 scale (the fist of five method). The skill runs a complexity check: no fives allowed. Fours get reviewed and split into threes where possible. If a task can’t be split below 4, it probably needs more research or a different approach.
The skill also runs a quality checklist before presenting the plan: completeness check, SOLID/DRY review, and a lessons check that verifies the plan doesn’t repeat known mistakes from previous sprints.
Before the plan reaches me, it goes through cross-model validation. The skill sends the draft plan to Gemini via a validation script that checks for missing details, logical gaps, and architectural issues. A second model without deep codebase context is good at catching things the planning model might overlook: race conditions, edge cases, N+1 queries, missing error paths. Claude addresses the feedback and builds the final plan that gets presented to me.
For the LLM client sprint, the plan came back with 5 milestones totaling 45 SP:
| Milestone | Title | SP |
|---|---|---|
| M1 | Core Module: Provider, ModelRef, Metrics, Retriers | 6 |
| M2 | ModelFactory and LlmRequest | 7 |
| M3 | Update Model Defaults and Configs | 10 |
| M4 | Migrate LLM Callers from lamb to services/llm | 14 |
| M5 | Drop Legacy Models and Remove lamb | 8 |
| Total | 45 SP |
The milestones follow the dependency chain: first build the foundation types (provider enum, model reference, metrics), then the factory and request handler, then migrate configs to use new defaults, then migrate all 30+ callers, and finally delete the old module.
I reviewed the plan and saw the ModelFactory used a match/case dispatch with each provider class imported inside its case branch. I left feedback:
_build_modelshould be extracted to a separate class. No lazy imports, with proper non-lazy imports app will fail if deps aren’t installed at build time, not at runtime. Can we make a builder class likeLlmRequestwhich orchestrates batch and retriers via DI with defaults?
The skill iterated on the plan, and I approved. This planning session is one Claude Code session. Then I start a new session for implementation.
/implement: Execution
The implementation skill starts by reading ALL lessons from previous sprints. This is the learning injection point. Before writing a single line of code, the agent knows what went wrong before and what rules to follow.
Then it confirms scope and dependencies, and executes milestones sequentially. Each task gets a checklist. DoD checkboxes are marked as the agent completes them.
When the dependency graph allows it, the skill delegates work to parallel sub-agents. Independent milestones run simultaneously through specialized agents (be-dev, fe-dev in my case). Each sub-agent gets its own clean context with just what it needs: the milestone section from the plan, relevant architectural decisions, applicable lessons, and the key files to read. This does two things: the main session stays focused on coordination instead of drowning in implementation details, and each agent gets the right model and a fresh context window for its specific domain. No context rot from a session that’s been actively boopin’ for hours.
After every milestone the agent commits the code, which triggers pre-commit hooks: tests, linters (ruff), type checkers (basedpyright). If anything fails, the agent fixes the issue before moving to the next milestone.
Code Review
This is the human ceremony. No skill forces it. You just have to do it.
Plan review and code review are connected. Code review compensates for what plan review missed. If a design issue slipped through plan review, catching it at code review is fine. Not ideal, but the two stages together cover more ground than either alone.
After the agent finishes implementing, I read the diff. All of it. I open ~/Claude/Notebook.md and write bullet points for everything I want to change as I go through the code. When I’m done reviewing, I paste the whole list into Claude as one message. Batch feedback beats trickle feedback.
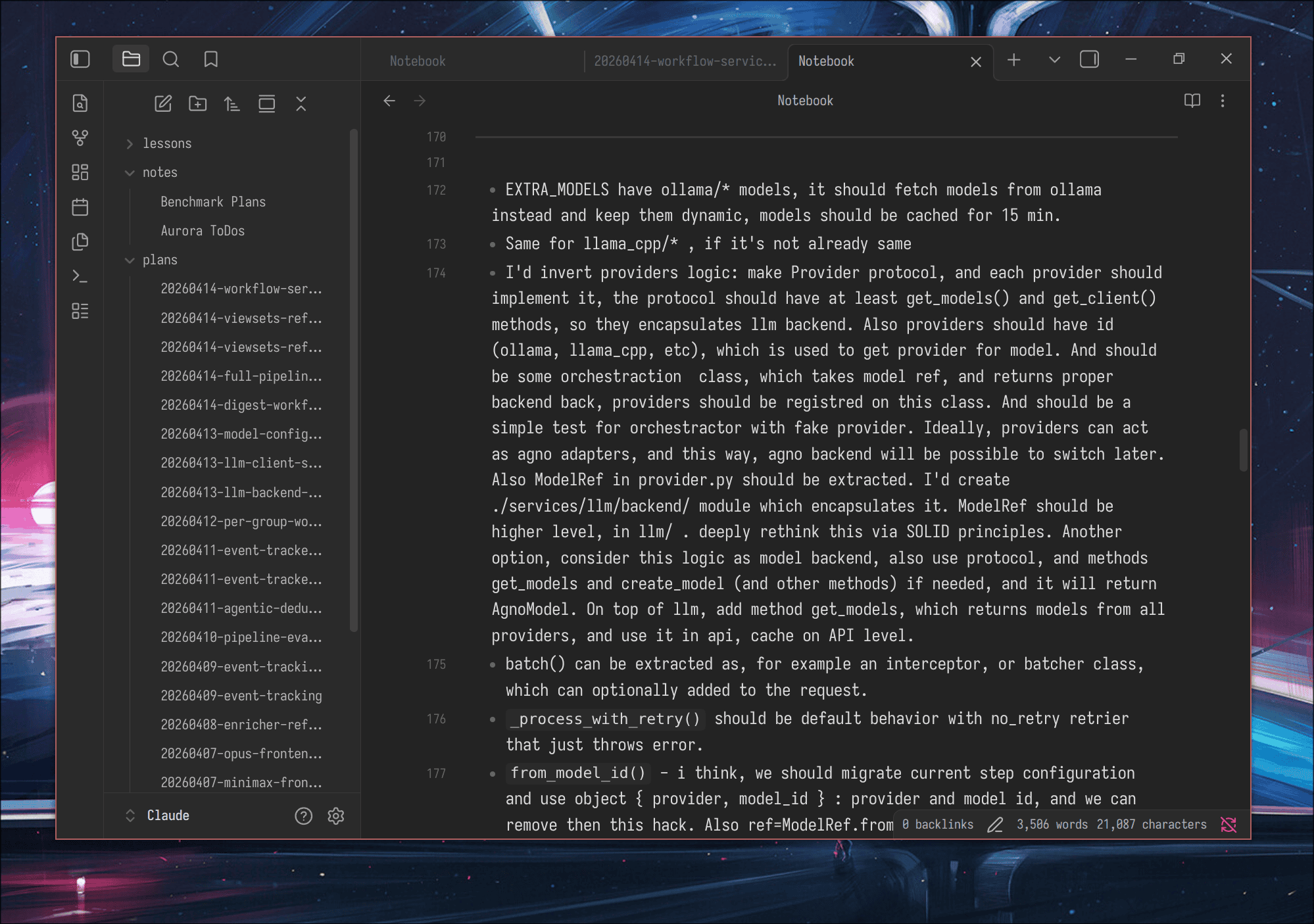
- For registry in
backend/__init__.py, why can’t you just create a class instance and export it? The hack withglobalis overengineeringModelRefandModelConfigare two types for the same concept, merge them. Why do we need to serializeModelConfigto str at all?_migrate_model_idis duplicated in many places. Can we just create a database migration that runs once instead?
Not “fix this.” Why it’s wrong, what the fix looks like, specific enough that the agent doesn’t have to guess.
The agent addresses feedback, I review again, usually two or three rounds. This is where most architectural issues get caught. The retro later picks up this feedback from the session context, so nothing is lost.
After code review is done, the session typically sits at 10-15% context usage (thanks to agent delegation keeping the main session light). That’s enough room to run the retrospective in the same session.
/retro: Retrospective
The retrospective skill reads the plan, the git diff, and the full session history, which includes all my code review feedback. It takes the feedback from code review iterations and any additional observations I provide, and structures everything into: what went well, what went wrong (with explicit root causes), and action items.
Since the retro runs in the same session as the implementation, it already has my code review comments as indirect input. I flag anything the code review missed or broader observations.
The skill also checks whether CLAUDE.md conventions contributed to any issues. In my experience, stale CLAUDE.md is one of the biggest contributors to bad AI-generated code. A convention that was true three sprints ago but no longer matches the codebase silently misleads every future session.
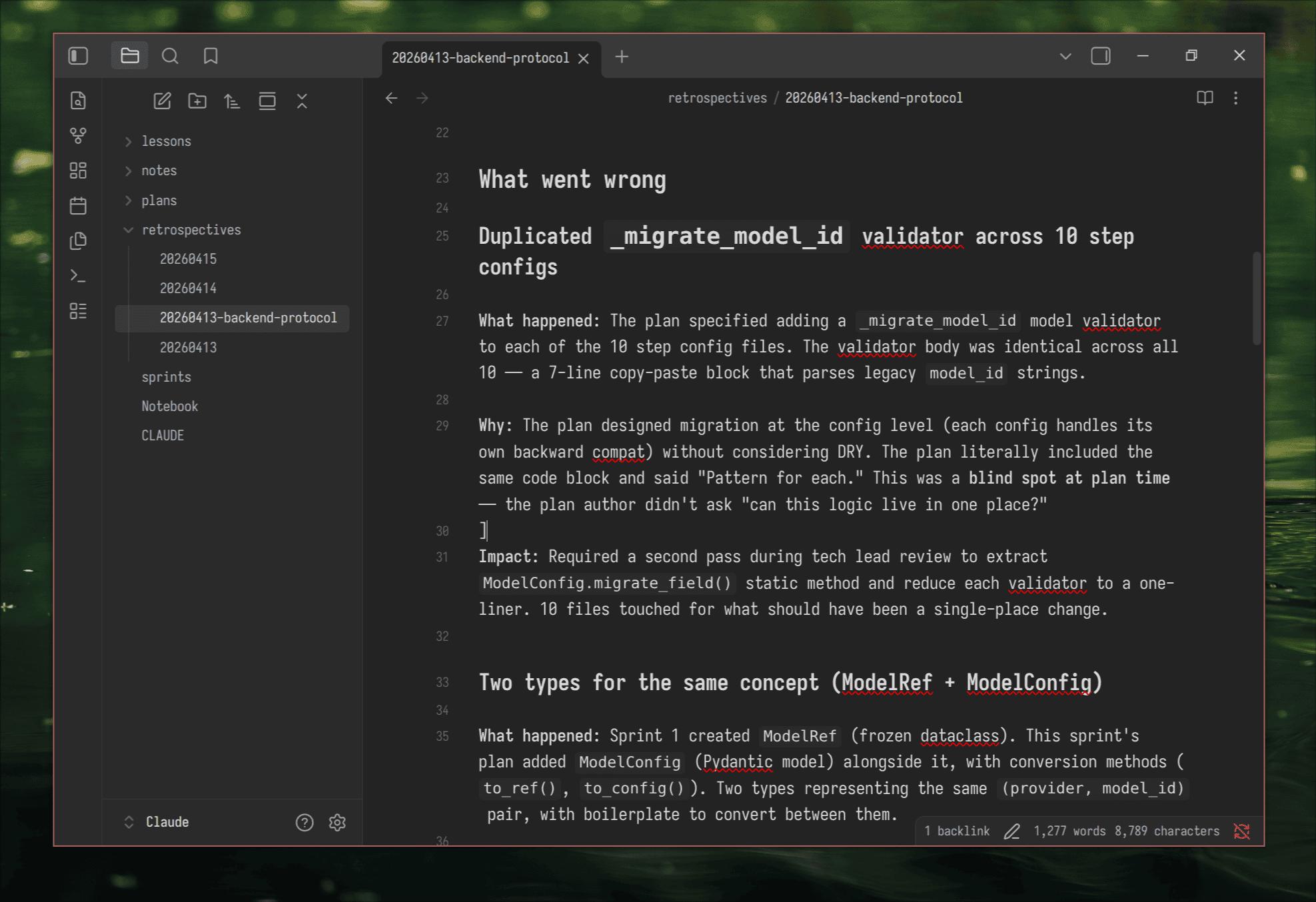
For the LLM client sprint, my code review had flagged the legacy Provider(StrEnum) design, scattered defaults, and hardcoded models. The retro picked that up and added root cause analysis:
Root cause: Ported existing patterns instead of designing the target abstraction from SOLID principles. The plan said “replace module” but didn’t challenge the old data patterns or specify what the clean architecture should look like.
That’s specific. It names what happened, why, and what the plan should have done differently. The next sprint’s plan can directly address it.
/lessons: Lesson Extraction
A retrospective is specific to one sprint, one project, one set of files. The lessons skill takes that specificity and generalizes it into rules that apply across projects and sessions.
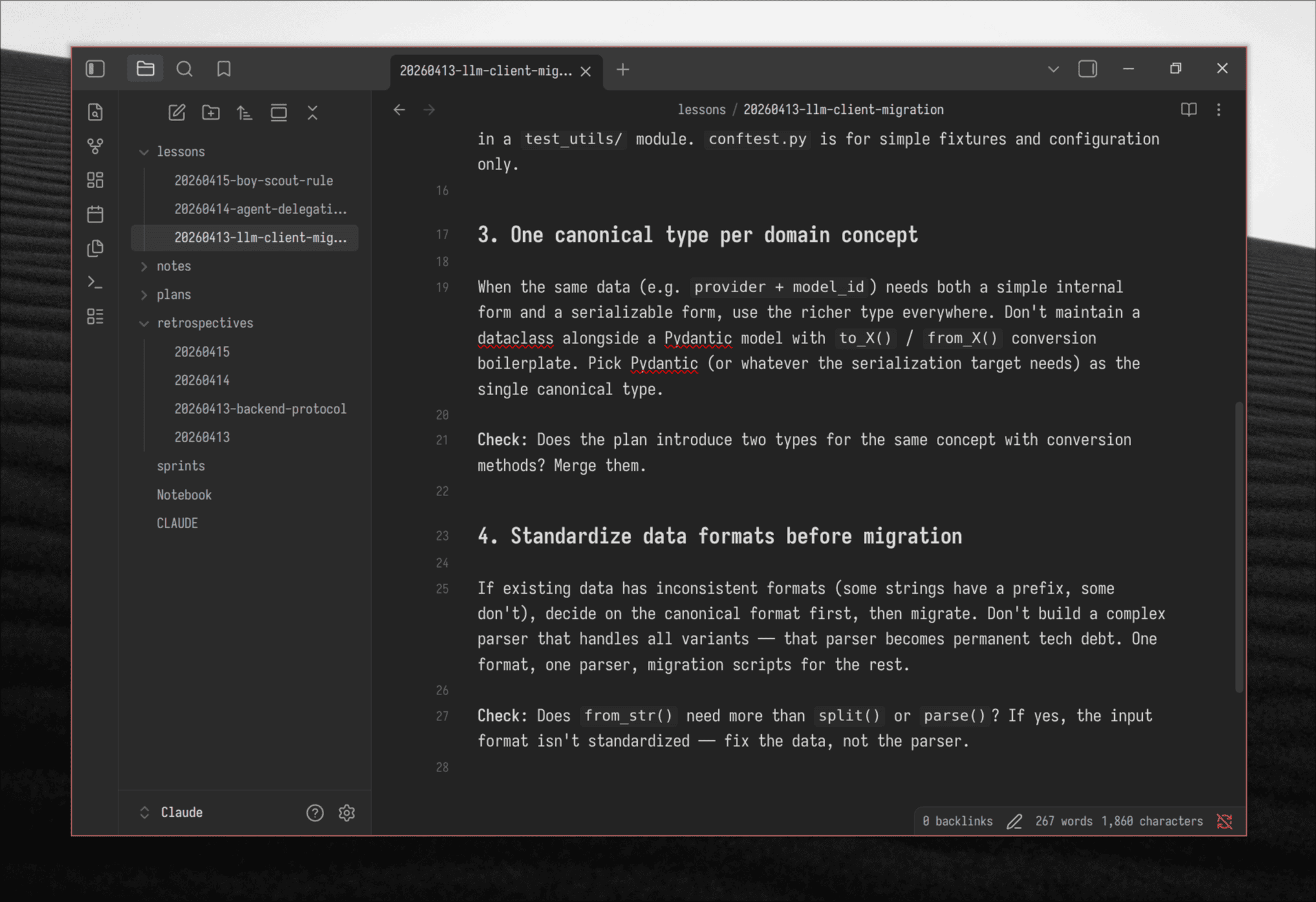
Where a retro says “the _migrate_model_id validator was copy-pasted across 10 step config files,” the corresponding lesson says:
### When a plan repeats a code block for N files, extract it first
Don't implement duplication and clean it up later. If the plan says
"add this to each of N files," that's a code smell at plan time.
Check: Does any task description repeat the same code change across
multiple files? Extract a shared function/mixin first.
The lesson drops the project-specific details (_migrate_model_id, step configs) and keeps the transferable rule. It gets saved to ~/Claude/lessons/ and placed into the right category. The next time /grooming runs, it reads all lessons and checks the new plan against them.
The skill maintains a clear three-way separation:
- Skills encode methodology (how to plan, how to review, how to extract lessons)
- Lessons encode experience (what went wrong, generalized into reusable rules)
- CLAUDE.md encodes project-specific practices, conventions, and constraints
The lessons skill can also update the skills themselves. If a retrospective reveals a gap in the planning methodology, the lesson doesn’t just say “remember this next time.” It proposes a change to the /grooming skill’s checklist or template. This feedback loop means each sprint doesn’t just improve the next plan. It improves the planning process itself.
Story Points and Metrics
Story points here measure the total complexity that both human and agent need to handle to deliver a plan: planning, implementation, code review, addressing feedback, running the retro. Same concept as in scrum, used for velocity tracking and estimating work volume.
I tested the /grooming skill across different models (Opus, GLM 5.1, MiniMax-M2.7) for the same feature. Each model gave very different story point estimates. That’s fine. What matters is using a consistent model for estimation so you can analyze velocity over time. Like keeping the same team.
A 60 SP plan means a full day of boopin’: reviewing plans, reading diffs, writing feedback, iterating. It’s not possible to do two 60 SP sprints in one day. An 8 SP plan is a quick afternoon task. Over weeks, the fluctuations smooth out and the estimates become reliable.
Tracking Velocity
The sprints.md file acts as a velocity dashboard. Each completed sprint gets a row with its goal, plan reference, total SP, status, and business goal outcome.
Over time, this data answers real questions:
- Daily velocity: how many SP completed per day, aggregated across sprints. After a few weeks, you know your throughput.
- Velocity trend: is throughput improving, stable, or declining? If it drops after a model update, you see it immediately.
- Realistic estimation: “This feature is 45 SP, so it’s a full day of work” stops being a guess and starts being grounded in data.
- Sprint success rate: tracked separately from completion. A sprint can be DONE but FAIL if the feature doesn’t work as intended.
- Review burden: your actual bottleneck metric. How many SP can you review per day before quality drops?
This is data that doesn’t exist in vibe coding. You can’t improve what you don’t measure.
The Self-Learning Loop
The cycle:
/groomingcreates a plan- Human reviews the plan
/implementexecutes the plan- Human does code review
/retroanalyzes the sprint/lessonsextracts rules- Next
/groomingreads those rules before writing the next plan
I split work into two sessions. One for steps 1-2, another for steps 3-7.
This is where the system pays off. The agent reads its own history and avoids repeating mistakes.
Here’s a real chain of four sprints on the same codebase where each sprint’s failure became the next sprint’s guardrail:
Sprint 1: LLM Client Service (45 SP). The implementation worked, but during code review I found issues: a Provider(StrEnum) that still had legacy entries like OLLAMA_CLOUD, DEFAULT_* config values scattered in code instead of Pydantic schema defaults, models hardcoded instead of fetched dynamically. The code worked but the design was a port of old patterns, not a clean abstraction. The retro picked up my code review feedback and did root cause analysis: the plan said “replace module” but didn’t specify the target architecture. Lesson extracted: “Design the target abstraction before mapping old code. Start from SOLID principles.”
Sprint 2: Backend Protocol Refactoring (49 SP). The plan applied Sprint 1’s lesson, designing a BackendRegistry that satisfies Open/Closed (add a provider by creating one file). During code review, I flagged several things: a hack to create a singleton registry in __init__.py, ModelRef and ModelConfig were two types for the same concept with conversion boilerplate, and _migrate_model_id was copy-pasted across 10 config files. The retro generalized my feedback into patterns. Lesson extracted: “One canonical type per domain concept” and “When a plan repeats a code block for N files, extract it first.”
Sprint 3: Viewsets Refactoring (52 SP). The plan included code sketches showing the target API. During code review, I found agents had copied those sketches as literal implementations, including a wrong type annotation. The retro identified the root cause: plan sketches propagate errors because agents treat them as copy-paste templates. Lesson extracted: “Plan sketches should be interfaces, not implementations.”
Sprint 4: Workflow Service Extraction (34 SP). Clean extraction, zero regressions, 321 tests green. But the verification step revealed pre-existing broken tests in an adjacent module. The agent dismissed them as “not our problem.” I flagged this in the retro. Lesson extracted: “When pre-existing failures are discovered during verification, present them to the user. Don’t dismiss, don’t silently fix.”
Boris Cherny, the creator of Claude Code, describes a similar pattern: “Anytime we see Claude do something incorrectly we add it to the CLAUDE.md. Claude is eerily good at writing rules for itself.” The difference with the skill system is that rule extraction is automated. The /retro and /lessons skills do the reflection and codification instead of you copy-pasting from chat logs into CLAUDE.md.
The key insight: retrospectives alone aren’t enough. You need the extraction step (lessons) and the injection step (reading lessons at plan and implement time). Without both, the loop doesn’t close. The skill system is the scaffolding.
Build Your Own
Here’s roughly how my journey went. You can compress it, but the order matters.
Start with /grooming. This was the first skill I built, and it had the biggest immediate impact. Claude Code already makes plans internally, but I wanted to own the artifacts, control the planning methodology, and iterate on the output template. The skill externalizes plans as markdown files I can review, annotate, and version.
Add agent delegation. Long implementation sessions cause context rot. The agent starts strong, but after thousands of tokens of implementation detail, it loses track of the plan. I started delegating milestones to sub-agents, each with a clean context containing just their scope. The main session stays light and focused on coordination. See /implement for how this is structured.
Add story points. I had the /grooming skill estimate each task on a 1-5 scale and produce a summary table. Mostly for fun at first, but it quickly became useful for gauging how much work I was signing up for and tracking throughput over time.
Add /retro and /lessons. This is where the self-learning loop closed. After a sprint, I run /retro in the same session (context is light thanks to agent delegation). It reads the plan, the diff, and my code review feedback, then produces a structured retrospective. Then /lessons extracts generalized rules. Next sprint, /grooming reads those rules before writing the plan.
Tune over time. The skills update themselves. /retro reviews the /grooming skill and suggests improvements. Lessons feed back into skill design. I’ve iterated on these skills for weeks and they keep getting sharper.
Claude did most of the skill generation. I explained what I needed, gave examples, reviewed the output, and tuned. You can start from my skills or build your own from scratch. I’d recommend building your own with Claude’s help, since the skills evolve with your workflow and self-update through the retro/lessons loop. Starting from someone else’s skills gives you a reference, but your process will diverge quickly.
The ~/Claude directory is also a git repo. Plans, retros, and lessons are versioned markdown that I browse in Obsidian. You can see how the process evolved, which lessons came from which retrospectives, and track your velocity over time.
The core loop works. 19 plans, 4 retrospectives, 3 lesson files across 8 days of real use on a production project. The agent writes code that improves over time. That’s the difference between a tool and a process.
Further Reading
- Agentic Software Engineering: Foundational Pillars and a Research Roadmap – the SE 3.0 framing, ACE/AEE workbenches, BriefingScripts and MentorScripts as formal artifacts
- From Technical Debt to Cognitive and Intent Debt – the triple debt model for AI-assisted codebases
- A Taxonomy of Inefficiencies in LLM-Generated Code (ICSME 2025) – 5 categories, 19 subcategories of AI code inefficiencies across 492 snippets
- Human-In-the-Loop Software Development Agents (HULA) – Atlassian’s validation of plan-approve-implement with 663 Jira issues
- Building AI Coding Agents for the Terminal – scaffolding, context engineering, and persistent memory architecture
- Devil’s Advocate: Anticipatory Reflection for LLM Agents – proactive reflection reducing action trials by 45%
- ReCatcher: Regression Testing for LLM Code Generation – model updates causing up to 50% regression in code quality
A related large-scale study tracking 304,362 AI-authored commits found that 24.2% of AI-introduced defects survived long-term in repositories. The METR study showed developers believed they were 20% faster with AI tools but were actually 19% slower. ↩︎